Overview
I worked with Meta as a visual arts and design expert supporting the evaluation and improvement of image-based generative AI models. My work focused on providing expert visual critique, structured annotations, and quality auditing of AI-generated imagery used during the model’s post-training phase. Beyond annotation work, I contributed to the development of clearer visual quality standards and evaluation practices that helped align human reviewers with Meta’s model improvement goals. The objective was to ensure that human feedback — a critical component of the human-in-the-loop AI training process — reflected professional standards in visual design, composition, and aesthetic judgment.
Challenge
As Meta expanded development of generative image models, the evaluation process faced several challenges:- AI-generated images varied widely in visual coherence, composition, and stylistic accuracy
- Subtle issues in anatomy, lighting, perspective, or rendering required expert visual critique to identify
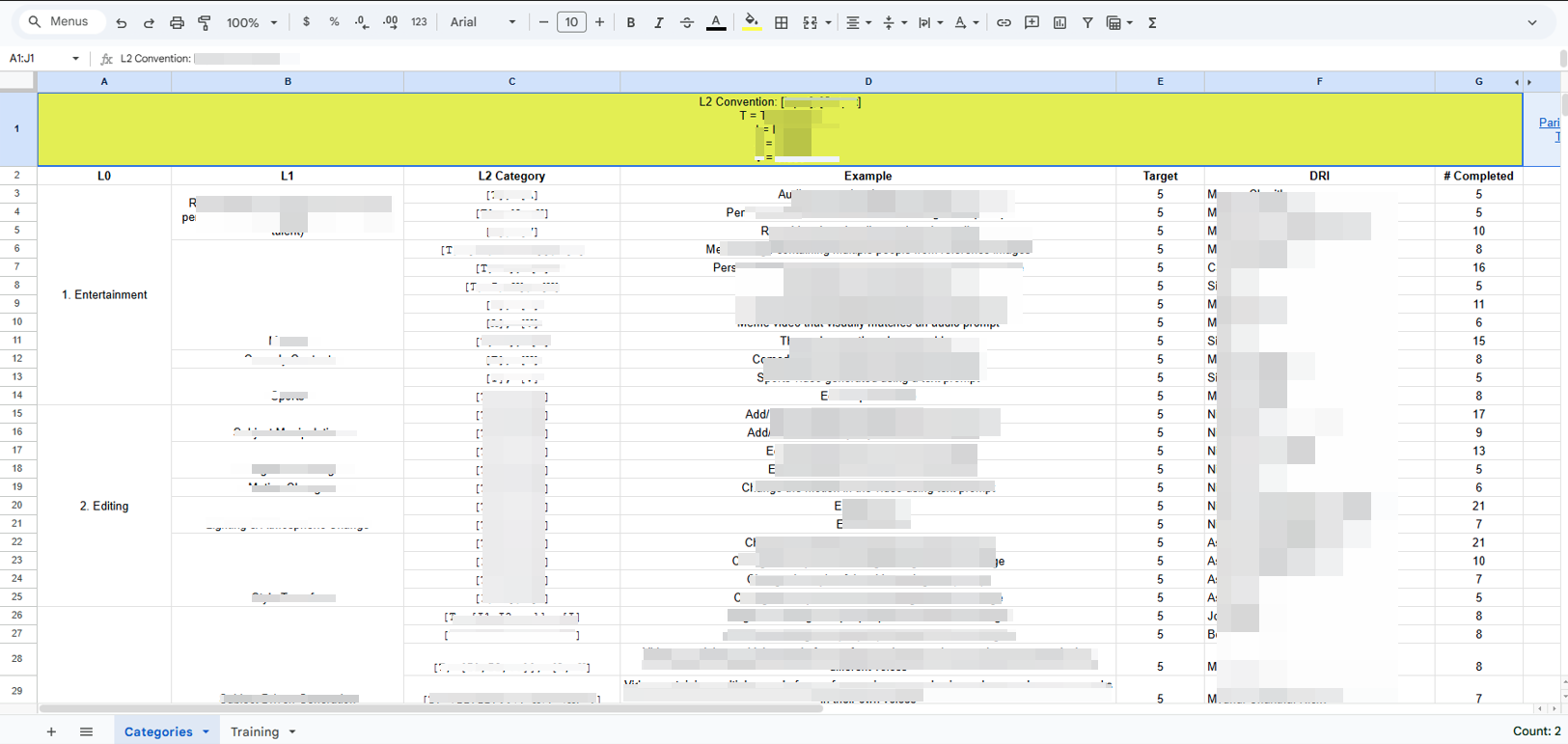
- Annotation work required consistent evaluation criteria to produce reliable training data
- Vendor-generated annotations required auditing to maintain quality and consistency
- Model improvement depended on highly accurate human feedback during post-training
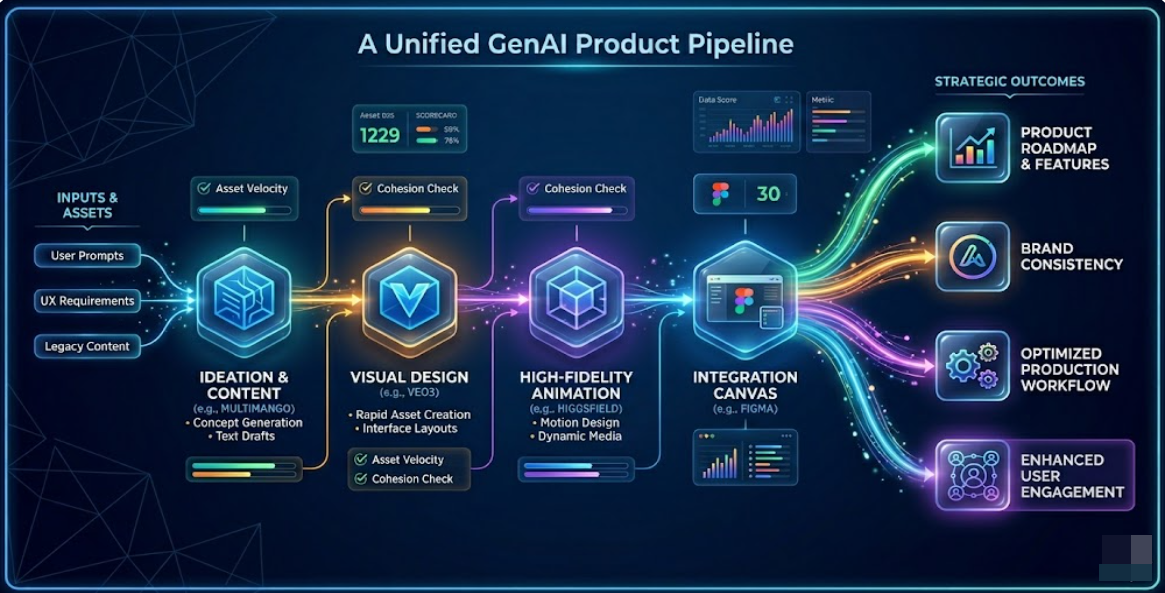
Approach
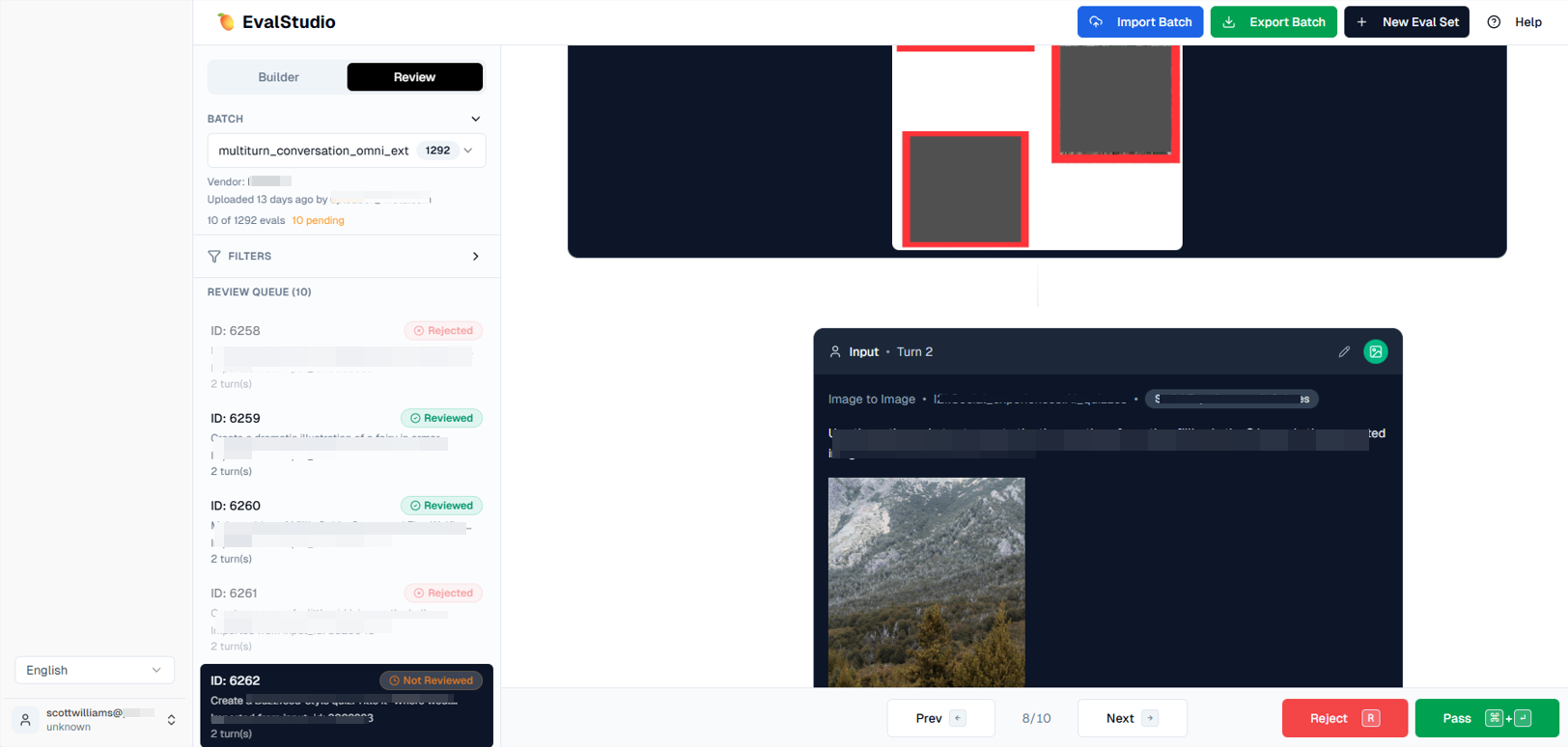
Human-in-the-Loop Model Evaluation
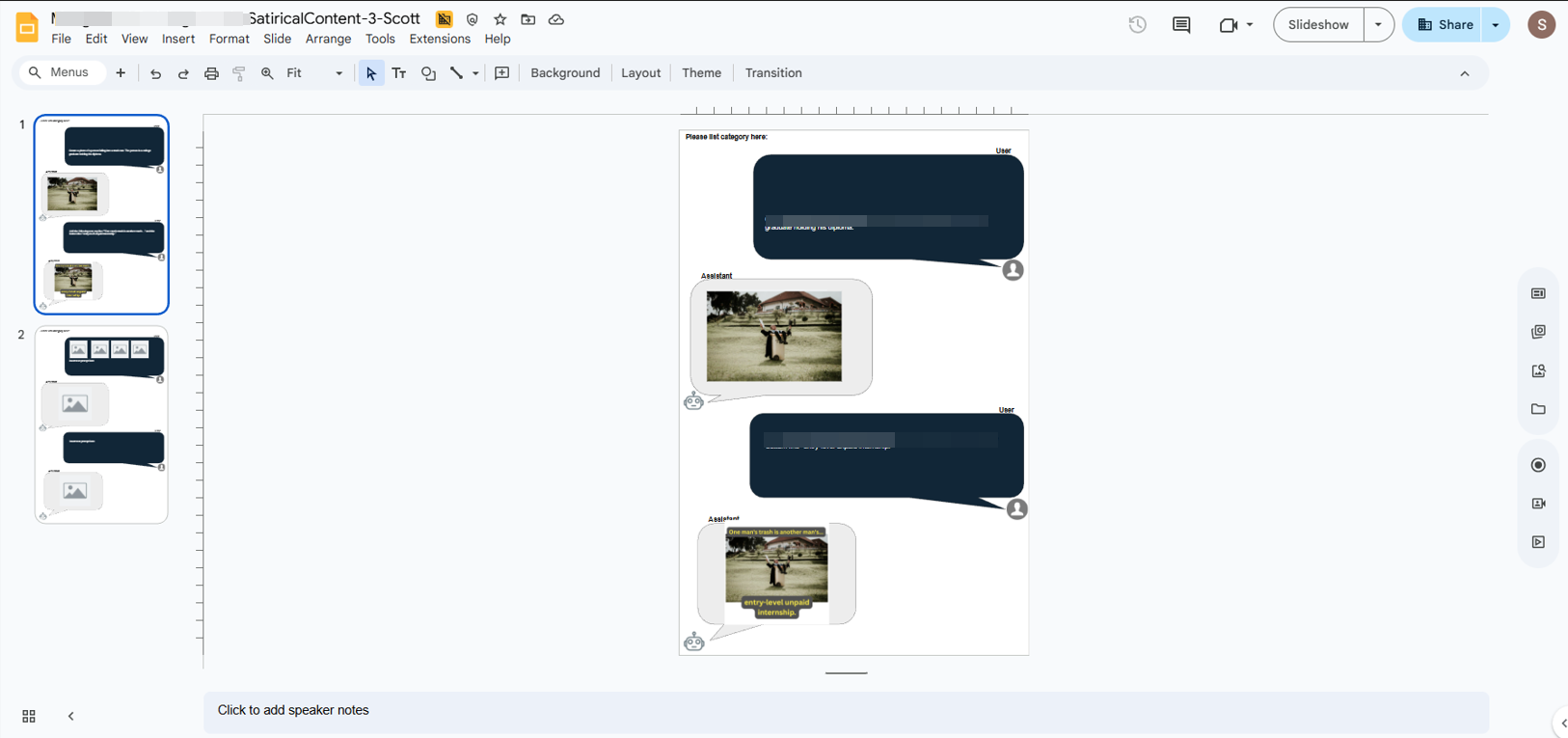
I conducted detailed reviews of AI-generated imagery, evaluating outputs using professional visual design and art critique methods.Evaluated:
- Composition and visual hierarchy
- Lighting, perspective, and spatial coherence
- Style fidelity and aesthetic alignment
- Rendering quality and artifact detection
- Accuracy of subject representation
Training Data Annotation
I contributed high-quality annotations used to improve the datasets guiding model behavior.Ensured:
- Labeling image attributes using structured criteria
- Identifying visual artifacts or model failure patterns
- Consistent learner experience
- Applying consistent standards across diverse visual styles
Quality Assurance & Calibration
To maintain reliability in the training pipeline, I also supported quality auditing and reviewer calibration.Supported:
- Reviewing vendor-generated annotations for accuracy and consistency
- Participating in regular calibration sessions with Meta teams to align evaluation standards
- Identifying ambiguous edge cases requiring clarification in evaluation criteria
Visual Quality Standards
I contributed to documentation that helped establish clearer visual evaluation guidelines across reviewers.Clarified:
- What defines high-quality AI-generated imagery
- Common model failure patterns
- Criteria for assessing composition, rendering, and style fidelity
- Best practices for structured visual critique
Tools Include
Higgsfield, Multimango, Parimango, Seedream, Veo3, ChatGPT, Midjourney, Heygen, KlingAI, Gemini, Google Suite, Artist.io, Pixelcut, Canva, Adobe Express, Handbrake, Pexels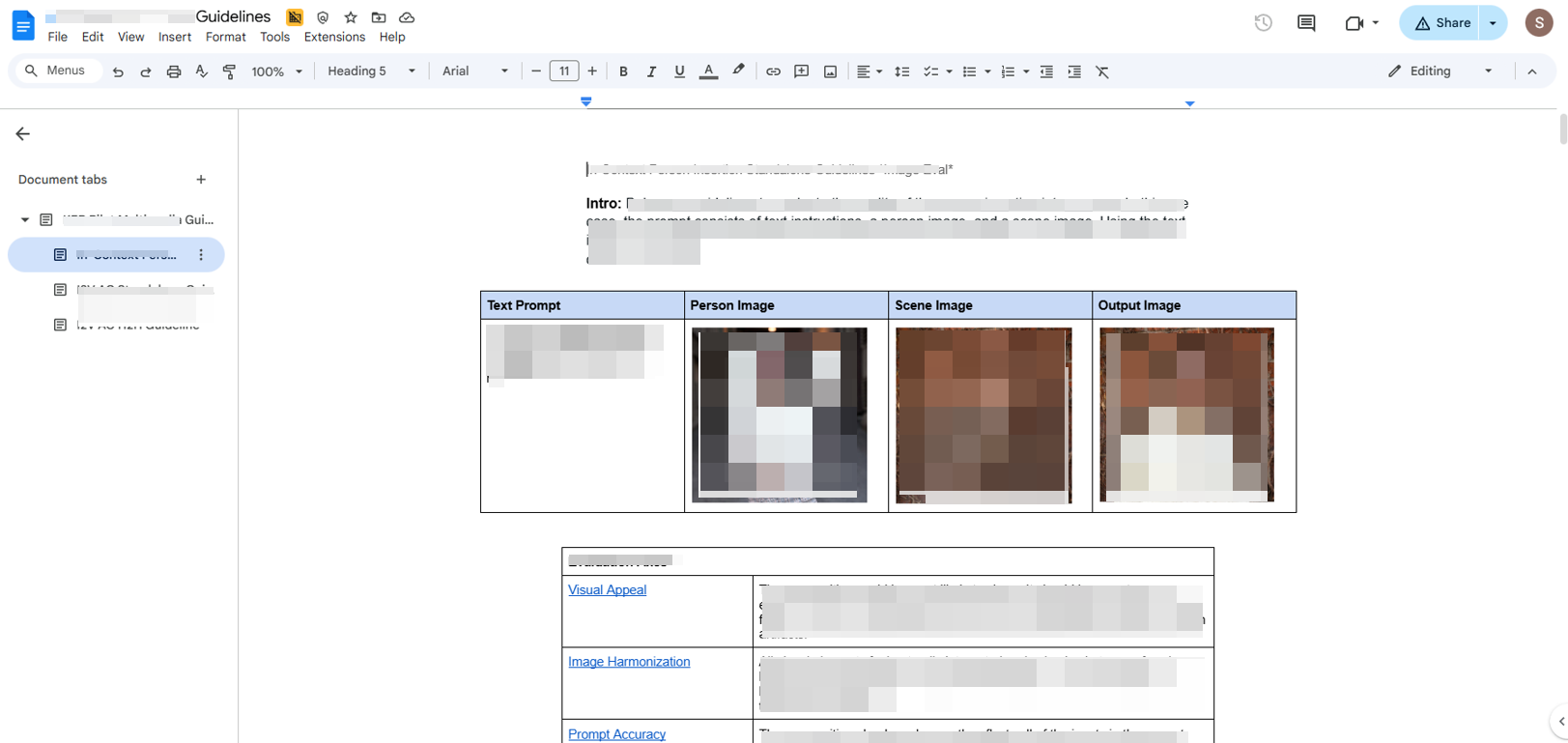
Results
- Delivered high-quality visual annotations supporting generative image model refinement
- Identified recurring rendering and composition issues in AI-generated outputs
- Improved reviewer alignment through calibration and evaluation guidelines
- Strengthened quality assurance within the model training feedback pipeline
- Contributed expert visual critique used to improve generative image outputs
Impact
This work supported the development of more visually coherent and reliable generative image models by ensuring that human feedback reflected professional standards in art and design.
By applying structured critique, quality governance, and expert visual evaluation, the project helped strengthen the human-in-the-loop training processes used to refine Meta’s next generation of AI image systems.